A COVID-19 é uma doença causada pelo coronavírus, denominado SARS-CoV-2, que apresenta um espectro clínico variando de infecções assintomáticas a quadros graves. De acordo com a Organização Mundial de Saúde, a maioria (cerca de 80%) dos pacientes com COVID-19 podem ser assintomáticos ou oligossintomáticos (poucos sintomas), e aproximadamente 20% dos casos detectados requer atendimento hospitalar por apresentarem dificuldade respiratória, dos quais aproximadamente 5% podem necessitar de suporte ventilatório.
Transmitido principalmente por meio de gotículas provenientes de tosses ou espirros de pessoas infectadas, a gravidade dos sintomas varia muito de pessoa para pessoa.

Com o objetivo de elevar a consciência situacional a respeito da COVID-19 no Brasil e no Mundo, irei realizar uma análise sobre os dados públicos da doença.
Obtenção dos Dados
Será utilizado como fonte dos dados o site Our World In Data, especializado em expor pesquisas empíricas e dados analíticos dos mais diversos assuntos ao redor do mundo. Os dados do site são atualizados diariamente, ou seja, haverá alterações no decorrer do estudo, pois, no momento da criação deste notebook, os dados foram extraídos no dia 29 de julho de 2020.
Dicionário de Variáveis
Para se ter uma melhor compreensão das variáveis utilizadas, abaixo um dicionário contendo a descrição de cada uma delas:
iso-code - Código de 3 letras de um determinado país.
continent - Continente do país.
location - Nome do país.
date - Data da observação.
total_cases - Total de casos confirmados de COVID-19.
new_cases - Novos casos confirmados de COVID-19.
total_deaths - Total de mortes atribuidas ao COVID-19.
new_deaths - Novas mortas atribuidas ao COVID-19.
total_cases_per_million - Total de casos confirmados de COVID-19 por 1,000,000 de pessoas.
new_cases_per_million - Novos casos confirmados de COVID-19 por 1,000,000 de pessoas.
total_deaths_per_million - Total de mortes atribuidas ao COVID-19 por 1,000,000 de pessoas.
new_deaths_per_million - Novas mortes atribuidas ao COVID-19 por 1,000,000 de pessoas.
total_tests - Total de testes para COVID-19.
new_tests - Novos testes para COVID-19.
new_tests_smoothed - Novos testes para COVID-19(7 dias suavizado). Para países que não reportam os dados do teste diariamente, assumimos que o teste mudou igualmente diariamente em qualquer período em que nenhum dado foi relatado. Isso produz uma série completa de números diários, que são calculados como média em uma janela de 7 dias consecutivos.
total_tests_per_thousand - Total de testes para COVID-19 por 1,000 pessoas.
new_tests_per_thousand - Novos testes para COVID-19 por 1,000 pessoas.
new_tests_smoothed_per_thousand - Novos testes para COVID-19(7 dias suavizado) por 1,000 pessoas.
tests_units - Unidades usadas pelo local para relatar seus dados de teste.
stringency_index - Índice de estresse da resposta do governo: medida composta baseada em 9 indicadores de resposta, incluindo fechamento de escolas, fechamento de locais de trabalho e proibições de viagens, redimensionados para um valor de 0 a 100 (100 = resposta mais estrita).
population - População em 2020.
population_density - Número de pessoas divididas por área terrestre, medida em quilômetros quadrados, no ano mais recente disponível.
median_age - Idade média da população, projeção da ONU para 2020.
aged_65_older - Proporção da população com 65 anos ou mais, ano mais recente disponível.
aged_70_older - Percentagem da população com 70 anos ou mais em 2015.
gdp_per_capita - Produto interno bruto com paridade do poder de compra (dólares internacionais constantes de 2011), último ano disponível.
extreme_poverty - Percentagem da população que vive em extrema pobreza, último ano disponível desde 2010.
cardiovasc_death_rate - Taxa de mortalidade por doenças cardiovasculares em 2017.
diabetes_prevalence - Prevalência de diabetes (% da população entre 20 e 79 anos) em 2017.
female_smokers - Percentagem de mulheres que fumam, último ano disponível.
male_smokers - Proporção de homens que fumam, último ano disponível.
handwashing_facilities - Proporção da população com instalações básicas de lavagem das mãos nas instalações, último ano disponível.
hospital_beds_per_thousand - Camas de hospital por 1.000 pessoas, último ano disponível desde 2010.
life_expectancy - Expectativa de vida no nascimento em 2019.
Importando os dados da COVID-19
Iremos utilizar o repositório do Github que é atualizado diariamente https://github.com/owid/covid-19-data/tree/master/public/data e usaremos o formato csv neste projeto.
# importar as bibliotecas necessárias
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# importar o dataset para um DataFrame
df = pd.read_csv("https://covid.ourworldindata.org/data/owid-covid-data.csv")
Análise Exploratória dos Dados
Iremos conhecer agora como os dados foram estruturados, e se tiver a necessidade tratar suas colunas e apresentar algumas informações. Lembrando que o dataset utilizado está atualizado até a data que foi feita essa análise, dia 29 de julho de 2020.
Análise Exploratória Inicial
# visualizar as 5 primeiras entradas
df.head()
| iso_code | continent | location | date | total_cases | new_cases | total_deaths | new_deaths | total_cases_per_million | new_cases_per_million | total_deaths_per_million | new_deaths_per_million | new_tests | total_tests | total_tests_per_thousand | new_tests_per_thousand | new_tests_smoothed | new_tests_smoothed_per_thousand | tests_units | stringency_index | population | population_density | median_age | aged_65_older | aged_70_older | gdp_per_capita | extreme_poverty | cardiovasc_death_rate | diabetes_prevalence | female_smokers | male_smokers | handwashing_facilities | hospital_beds_per_thousand | life_expectancy | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | AFG | Asia | Afghanistan | 2019-12-31 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 38928341.0 | 54.422 | 18.6 | 2.581 | 1.337 | 1803.987 | NaN | 597.029 | 9.59 | NaN | NaN | 37.746 | 0.5 | 64.83 |
| 1 | AFG | Asia | Afghanistan | 2020-01-01 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 0.0 | 38928341.0 | 54.422 | 18.6 | 2.581 | 1.337 | 1803.987 | NaN | 597.029 | 9.59 | NaN | NaN | 37.746 | 0.5 | 64.83 |
| 2 | AFG | Asia | Afghanistan | 2020-01-02 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 0.0 | 38928341.0 | 54.422 | 18.6 | 2.581 | 1.337 | 1803.987 | NaN | 597.029 | 9.59 | NaN | NaN | 37.746 | 0.5 | 64.83 |
| 3 | AFG | Asia | Afghanistan | 2020-01-03 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 0.0 | 38928341.0 | 54.422 | 18.6 | 2.581 | 1.337 | 1803.987 | NaN | 597.029 | 9.59 | NaN | NaN | 37.746 | 0.5 | 64.83 |
| 4 | AFG | Asia | Afghanistan | 2020-01-04 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 0.0 | 38928341.0 | 54.422 | 18.6 | 2.581 | 1.337 | 1803.987 | NaN | 597.029 | 9.59 | NaN | NaN | 37.746 | 0.5 | 64.83 |
# visualizar as 5 ultimas linhas
df.tail()
| iso_code | continent | location | date | total_cases | new_cases | total_deaths | new_deaths | total_cases_per_million | new_cases_per_million | total_deaths_per_million | new_deaths_per_million | new_tests | total_tests | total_tests_per_thousand | new_tests_per_thousand | new_tests_smoothed | new_tests_smoothed_per_thousand | tests_units | stringency_index | population | population_density | median_age | aged_65_older | aged_70_older | gdp_per_capita | extreme_poverty | cardiovasc_death_rate | diabetes_prevalence | female_smokers | male_smokers | handwashing_facilities | hospital_beds_per_thousand | life_expectancy | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 33412 | NaN | NaN | International | 2020-02-28 | 705.0 | 0.0 | 4.0 | 0.0 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 33413 | NaN | NaN | International | 2020-02-29 | 705.0 | 0.0 | 6.0 | 2.0 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 33414 | NaN | NaN | International | 2020-03-01 | 705.0 | 0.0 | 6.0 | 0.0 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 33415 | NaN | NaN | International | 2020-03-02 | 705.0 | 0.0 | 6.0 | 0.0 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 33416 | NaN | NaN | International | 2020-03-10 | 696.0 | -9.0 | 7.0 | 1.0 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
# visualizar o tamanho do Dataframe
df.shape
(33417, 34)
Há 31704 linhas e 34 colunas.
# visualizar as colunas
df.columns
Index(['iso_code', 'continent', 'location', 'date', 'total_cases', 'new_cases',
'total_deaths', 'new_deaths', 'total_cases_per_million',
'new_cases_per_million', 'total_deaths_per_million',
'new_deaths_per_million', 'new_tests', 'total_tests',
'total_tests_per_thousand', 'new_tests_per_thousand',
'new_tests_smoothed', 'new_tests_smoothed_per_thousand', 'tests_units',
'stringency_index', 'population', 'population_density', 'median_age',
'aged_65_older', 'aged_70_older', 'gdp_per_capita', 'extreme_poverty',
'cardiovasc_death_rate', 'diabetes_prevalence', 'female_smokers',
'male_smokers', 'handwashing_facilities', 'hospital_beds_per_thousand',
'life_expectancy'],
dtype='object')
# visualizar os tipos das variáveis
df.dtypes
iso_code object
continent object
location object
date object
total_cases float64
new_cases float64
total_deaths float64
new_deaths float64
total_cases_per_million float64
new_cases_per_million float64
total_deaths_per_million float64
new_deaths_per_million float64
new_tests float64
total_tests float64
total_tests_per_thousand float64
new_tests_per_thousand float64
new_tests_smoothed float64
new_tests_smoothed_per_thousand float64
tests_units object
stringency_index float64
population float64
population_density float64
median_age float64
aged_65_older float64
aged_70_older float64
gdp_per_capita float64
extreme_poverty float64
cardiovasc_death_rate float64
diabetes_prevalence float64
female_smokers float64
male_smokers float64
handwashing_facilities float64
hospital_beds_per_thousand float64
life_expectancy float64
dtype: object
Nessa verificação dos tipos de variáveis, podemos verificar que a coluna Date está como tipo object, vamos fazer o tratamento da mesma e alterá-la para o tipo data para melhor manipulação.
#transformar o tipo da variavel date para o tipo datetime
df.date = pd.to_datetime(df.date)
df.dtypes
iso_code object
continent object
location object
date datetime64[ns]
total_cases float64
new_cases float64
total_deaths float64
new_deaths float64
total_cases_per_million float64
new_cases_per_million float64
total_deaths_per_million float64
new_deaths_per_million float64
new_tests float64
total_tests float64
total_tests_per_thousand float64
new_tests_per_thousand float64
new_tests_smoothed float64
new_tests_smoothed_per_thousand float64
tests_units object
stringency_index float64
population float64
population_density float64
median_age float64
aged_65_older float64
aged_70_older float64
gdp_per_capita float64
extreme_poverty float64
cardiovasc_death_rate float64
diabetes_prevalence float64
female_smokers float64
male_smokers float64
handwashing_facilities float64
hospital_beds_per_thousand float64
life_expectancy float64
dtype: object
# verificar valores ausentes
(df.isnull().sum() / df.shape[0]).sort_values(ascending = False)
new_tests_per_thousand 0.688751
new_tests 0.688751
total_tests_per_thousand 0.681390
total_tests 0.681390
new_tests_smoothed_per_thousand 0.655265
new_tests_smoothed 0.655265
tests_units 0.632283
handwashing_facilities 0.588114
extreme_poverty 0.405542
male_smokers 0.294042
female_smokers 0.285483
stringency_index 0.188138
hospital_beds_per_thousand 0.181465
aged_65_older 0.113086
gdp_per_capita 0.110991
aged_70_older 0.104677
median_age 0.100039
cardiovasc_death_rate 0.099770
diabetes_prevalence 0.069216
population_density 0.045097
life_expectancy 0.013945
new_deaths_per_million 0.012539
total_deaths_per_million 0.012539
new_cases_per_million 0.012539
total_cases_per_million 0.012539
new_deaths 0.010623
total_deaths 0.010623
new_cases 0.010623
total_cases 0.010623
continent 0.008259
population 0.001915
iso_code 0.001915
date 0.000000
location 0.000000
dtype: float64
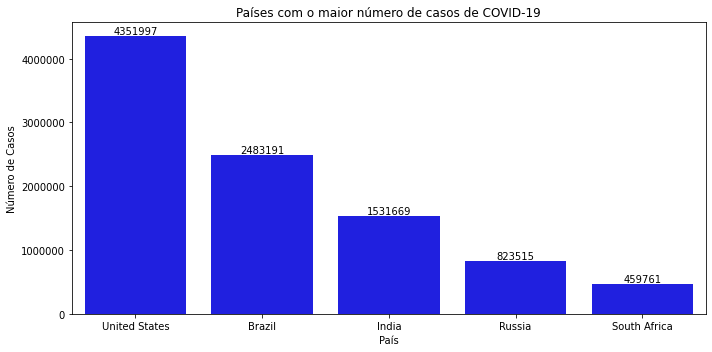
# ver para a data mais atual, quais os 5 países que tem mais casos
df.loc[df.date == '2020-07-29', ['location', 'total_cases']].sort_values(by="total_cases", ascending=False)[1:6]
| location | total_cases | |
|---|---|---|
| 31785 | United States | 4351997.0 |
| 4521 | Brazil | 2483191.0 |
| 14203 | India | 1531669.0 |
| 25210 | Russia | 823515.0 |
| 27706 | South Africa | 459761.0 |
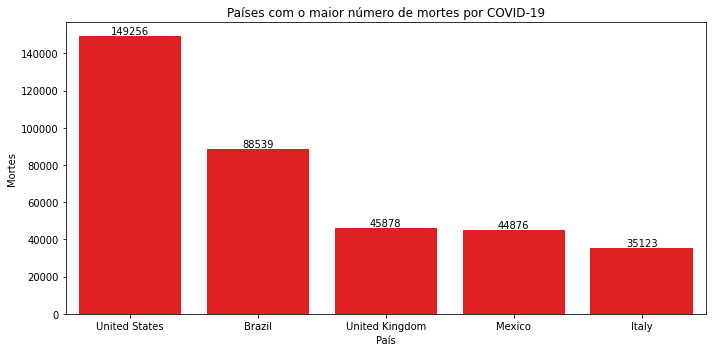
# ver para a data mais atual, quais os 5 países que tem mais mortes
df.loc[df.date=='2020-07-29', ['location', 'total_deaths']].sort_values(by="total_deaths", ascending=False)[1:6]
| location | total_deaths | |
|---|---|---|
| 31785 | United States | 149256.0 |
| 4521 | Brazil | 88539.0 |
| 31573 | United Kingdom | 45878.0 |
| 19953 | Mexico | 44876.0 |
| 15595 | Italy | 35123.0 |
###Plotagem de Gráficos
Vamos plotar gráficos para melhor visualização dos dados:
#plotar gráfico dos 5 primeiros países com o maior número de casos
fig, ax = plt.subplots(figsize=(10,5))
top5_cases = df.loc[df.date=='2020-07-29',['location', 'total_cases']].sort_values(by='total_cases', ascending=False)[1:6]
sns.barplot(x='location', y='total_cases',data=top5_cases, color="b")
#formatar o ax
ax.ticklabel_format(style='plain', axis='y')
ax.set_xlabel("País")
ax.set_ylabel("Número de Casos")
ax.set_title("Países com o maior número de casos de COVID-19")
#inserir o valor acima de cada barra
for index,data in enumerate(top5_cases['total_cases']):
ax.text(x=index , y=data, s=round(data), horizontalalignment='center',verticalalignment='bottom')
plt.tight_layout()
#plotar gráfico dos 5 primeiros países com o maior numero de mortes
fig, ax = plt.subplots(figsize=(10,5))
top5_deaths = df.loc[df.date=='2020-07-29',['location', 'total_deaths']].sort_values(by='total_deaths', ascending=False)[1:6]
sns.barplot(x='location', y='total_deaths',data=top5_deaths, color="r")
#formatar o ax
ax.set_xlabel("País")
ax.set_ylabel("Mortes")
ax.set_title("Países com o maior número de mortes por COVID-19")
#inserir o valor acima de cada barra
for index,data in enumerate(top5_deaths['total_deaths']):
ax.text(x=index , y=data, s=round(data), horizontalalignment='center',verticalalignment='bottom')
plt.tight_layout()
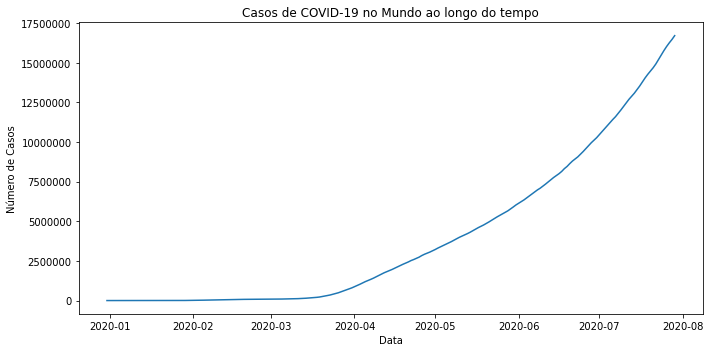
Vamos verificar como foi a evolução dos casos de COVID-19 no Mundo.
fig, ax = plt.subplots(figsize=(10,5))
ev = df.loc[df.location=='World',['date', 'total_cases']].sort_values(by='total_cases', ascending=True)
sns.lineplot(x='date', y='total_cases', data=ev)
ax.ticklabel_format(style='plain', axis='y')
ax.set(xlabel='Data')
ax.set(ylabel='Número de Casos')
ax.set_title("Casos de COVID-19 no Mundo ao longo do tempo")
plt.tight_layout()
#plotar gráfico de dispersão em relaçao ao PIB x número de mortes
fig, ax = plt.subplots(figsize=(8,5))
gdsp = df.loc[df.date=='2020-07-29',['gdp_per_capita', 'total_deaths']].sort_values(by='gdp_per_capita')
sns.scatterplot(x='gdp_per_capita', y='total_deaths', data=gdsp)
ax.ticklabel_format(style='plain', axis='y')
ax.set(xlabel='PIB')
ax.set(ylabel='Total de Mortes')
plt.tight_layout()
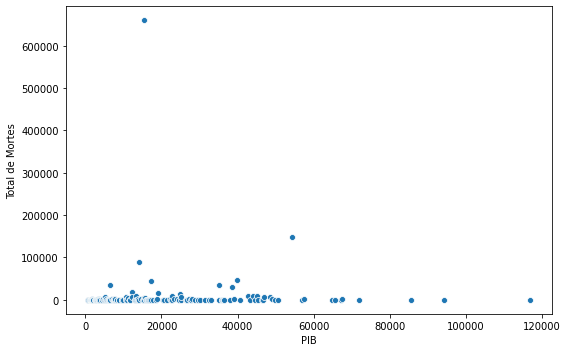
Lembrando que esse gráfico não é nada conclusivo, pois envolve fatores como proporção de testes, etc..
Análise Exploratória para o Brasil
Vamos fazer uma Análise Exploratória do Brasil:
#criar uma cópia do Dataframe apenas com o Brasil
df_brasil = df.loc[df.location == 'Brazil'].copy()
#visualizar as 5 primeiras linhas
df_brasil.head()
| iso_code | continent | location | date | total_cases | new_cases | total_deaths | new_deaths | total_cases_per_million | new_cases_per_million | total_deaths_per_million | new_deaths_per_million | new_tests | total_tests | total_tests_per_thousand | new_tests_per_thousand | new_tests_smoothed | new_tests_smoothed_per_thousand | tests_units | stringency_index | population | population_density | median_age | aged_65_older | aged_70_older | gdp_per_capita | extreme_poverty | cardiovasc_death_rate | diabetes_prevalence | female_smokers | male_smokers | handwashing_facilities | hospital_beds_per_thousand | life_expectancy | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 4310 | BRA | South America | Brazil | 2019-12-31 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 212559409.0 | 25.04 | 33.5 | 8.552 | 5.06 | 14103.452 | 3.4 | 177.961 | 8.11 | 10.1 | 17.9 | NaN | 2.2 | 75.88 |
| 4311 | BRA | South America | Brazil | 2020-01-01 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 0.0 | 212559409.0 | 25.04 | 33.5 | 8.552 | 5.06 | 14103.452 | 3.4 | 177.961 | 8.11 | 10.1 | 17.9 | NaN | 2.2 | 75.88 |
| 4312 | BRA | South America | Brazil | 2020-01-02 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 0.0 | 212559409.0 | 25.04 | 33.5 | 8.552 | 5.06 | 14103.452 | 3.4 | 177.961 | 8.11 | 10.1 | 17.9 | NaN | 2.2 | 75.88 |
| 4313 | BRA | South America | Brazil | 2020-01-03 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 0.0 | 212559409.0 | 25.04 | 33.5 | 8.552 | 5.06 | 14103.452 | 3.4 | 177.961 | 8.11 | 10.1 | 17.9 | NaN | 2.2 | 75.88 |
| 4314 | BRA | South America | Brazil | 2020-01-04 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 0.0 | 212559409.0 | 25.04 | 33.5 | 8.552 | 5.06 | 14103.452 | 3.4 | 177.961 | 8.11 | 10.1 | 17.9 | NaN | 2.2 | 75.88 |
Vamos identificar quando ocorreu o primeiro caso no Brasil:
df_brasil.loc[df_brasil.total_cases == 1.0].sort_values(by='date').head(1)
| iso_code | continent | location | date | total_cases | new_cases | total_deaths | new_deaths | total_cases_per_million | new_cases_per_million | total_deaths_per_million | new_deaths_per_million | new_tests | total_tests | total_tests_per_thousand | new_tests_per_thousand | new_tests_smoothed | new_tests_smoothed_per_thousand | tests_units | stringency_index | population | population_density | median_age | aged_65_older | aged_70_older | gdp_per_capita | extreme_poverty | cardiovasc_death_rate | diabetes_prevalence | female_smokers | male_smokers | handwashing_facilities | hospital_beds_per_thousand | life_expectancy | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 4367 | BRA | South America | Brazil | 2020-02-26 | 1.0 | 1.0 | 0.0 | 0.0 | 0.005 | 0.005 | 0.0 | 0.0 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 5.56 | 212559409.0 | 25.04 | 33.5 | 8.552 | 5.06 | 14103.452 | 3.4 | 177.961 | 8.11 | 10.1 | 17.9 | NaN | 2.2 | 75.88 |
- O primeiro caso de COVID-19 no Brasil ocorreu no dia 26-02-2020.
Vamos identificar quando ocorreu a primeira morte no Brasil:
df_brasil.loc[df_brasil.total_deaths == 1.0].sort_values(by='date').head(1)
| iso_code | continent | location | date | total_cases | new_cases | total_deaths | new_deaths | total_cases_per_million | new_cases_per_million | total_deaths_per_million | new_deaths_per_million | new_tests | total_tests | total_tests_per_thousand | new_tests_per_thousand | new_tests_smoothed | new_tests_smoothed_per_thousand | tests_units | stringency_index | population | population_density | median_age | aged_65_older | aged_70_older | gdp_per_capita | extreme_poverty | cardiovasc_death_rate | diabetes_prevalence | female_smokers | male_smokers | handwashing_facilities | hospital_beds_per_thousand | life_expectancy | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 4388 | BRA | South America | Brazil | 2020-03-18 | 291.0 | 57.0 | 1.0 | 1.0 | 1.369 | 0.268 | 0.005 | 0.005 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 60.65 | 212559409.0 | 25.04 | 33.5 | 8.552 | 5.06 | 14103.452 | 3.4 | 177.961 | 8.11 | 10.1 | 17.9 | NaN | 2.2 | 75.88 |
- A primeira morte por COVID-19 no Brasil ocorreu no dia 18-03-2020.
Vamos verificar quantos dias levou do primeiro caso a primeira morte:
df_brasil_tempo = df_brasil.date.loc[4334] - df_brasil.date.loc[4313]
df_brasil_tempo.days
21
- O tempo entre o primeiro caso e a primeira morte por COVID-19 no Brasil foi de 21 dias.
Vamos calcular a média do índice de mortalidade:
df_totald = df_brasil.loc[df.date == '2020-07-29', ['total_deaths']]
df_totalc = df_brasil.loc[df.date == '2020-07-29', ['total_cases']]
mortalidade = (df_totald.total_deaths / df_totalc.total_cases) * 100
print(round(mortalidade,2))
4521 3.57
dtype: float64
- O Brasil tem uma mortalidade de 3.57%.
###Plotagem de Gráficos
Vamos plotar gráficos para melhor visualização dos dados:
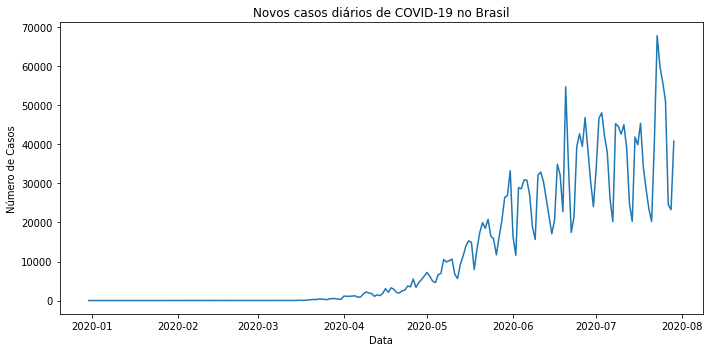
#plotar gráfico em linha com o número de novos casos diários
fig, ax = plt.subplots(figsize=(10,5))
sns.lineplot(x='date', y='new_cases', data=df_brasil)
#formatar o ax
ax.ticklabel_format(style='plain', axis='y')
ax.set(xlabel='Data')
ax.set(ylabel='Número de Casos')
ax.set_title("Novos casos diários de COVID-19 no Brasil")
plt.tight_layout()
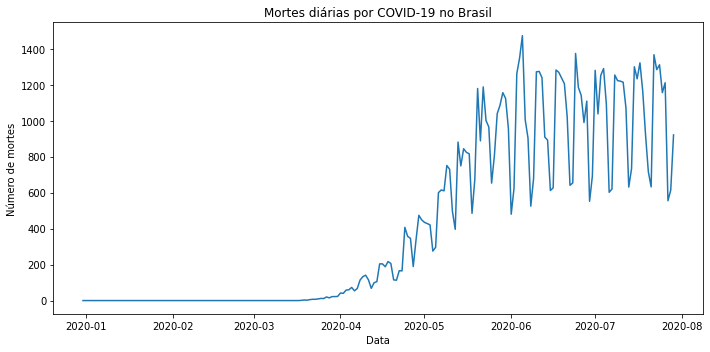
#plotar gráfico em linha com o número de mortes diárias
fig, ax = plt.subplots(figsize=(10,5))
sns.lineplot(x='date', y='new_deaths', data=df_brasil)
#formatar o ax
ax.set(xlabel='Data')
ax.set(ylabel='Número de mortes')
ax.set_title("Mortes diárias por COVID-19 no Brasil")
plt.tight_layout()
Conclusão
Infelizmente a Pandemia da COVID-19 continua em andamento, e enquanto não houver uma vacina eficaz a evolução da doença tende a ser mais rápida, apesar da queda de casos diários por conta da quarentena. Nessa análise, conseguimos visualizar informações importantes, como:
- Os 5 países com mais casos são:
- Estados Unidos - 4.351.997 de casos
- Brasil - 2.483.191 de casos
- India - 1.531.669 de casos
- Russia - 823.515 de casos
- África de Sul - 459.761 de casos
- Os 5 países com mais mortes são:
- Estados Unidos - 149.256 mortes
- Brasil - 88.539 mortes
- Reino Unido - 45.878 mortes
- Mexico - 44.876 mortes
- Itália - 35.123 mortes
-
O primeiro caso de COVID-19 no Brasil ocorreu no dia 26 de fevereiro de 2020.
-
A primeira morte por COVID-19 no Brasil ocorreu no dia 18 de março de 2020.
-
Levou cerca de 21 dias entre o primeiro caso e a primeira morte no Brasil.
- O Brasil tem um índice de mortalide de 3,57%.
Lembrando que esses dados são atualizados até o dia 29 de julho de 2020, e podem estar desatualizados dependendo da data em que esse notebook for lido.